



Written by Audrey Hansell and Maddy Brown, DIS Machine Learning Fall 2024
Introduction
Bike sharing systems have become increasingly common in cities across the US and all over the world. Bike sharing has helped reduce traffic congestion, encouraged people to be more active and allowed users to pick up a bike where they need it and leave it at their desired destinations. These systems can help locals and visitors alike, but only if there are enough bikes available. Luckily, bike sharing systems are able to collect data easily to more accurately predict how many bikes are needed at any given day and hour.
Data
In this blog post, we will discuss our methodology and results from applying regression models on bike sharing data from Capital Bike Share in Washington D.C., USA.* The dataset, which can be found here on Kaggle, includes over 17,000 data points measuring the amount of bikes needed per hour. Other notable features included the weather, the temperature outside, the day of the week and whether or not it was a holiday or a weekend. The data was gathered over two years by Capital Bikeshare System and features various weather conditions and a range of temperatures.
* Our code is also available in a Jupyter Notebook on GitHub here.
Features
The original dataset included 17 features in total (as listed below).
instant: record index
dteday: date
season: season
- 1: spring, 2: summer, 3: fall, 4: winter
yr: year
- 0 = 2011 and 1 = 2012
mnth: month
- Jan = 1, Feb = 2… Dec = 12
hr: hour
- 0 to 23
holiday: weather day is holiday or not
- according to dchr.dc.gov/page/holiday-schedule
weekday: day of the week
workingday: days of the week when businesses and organizations operate
- if day is neither weekend nor holiday = 1, otherwise = 0.
weathersit: weather situation (classified into groups below)
1: Clear, Few clouds, Partly cloudy, Partly cloudy
2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
temp: Normalized temperature in Celsius
- The values are divided to 41 (max)
atemp: Normalized feeling temperature in Celsius
- The values are divided to 50 (max)
hum: Normalized humidity
- The values are divided to 100 (max)
windspeed: Normalized wind speed
- The values are divided to 67 (max)
casual: count of casual users
registered: count of registered users
cnt: count of total rental bikes
- Includes both casual and registered
The date (dteday) column was the only column that was non-numeric and there were no null values in the dataset.
Data Distribution
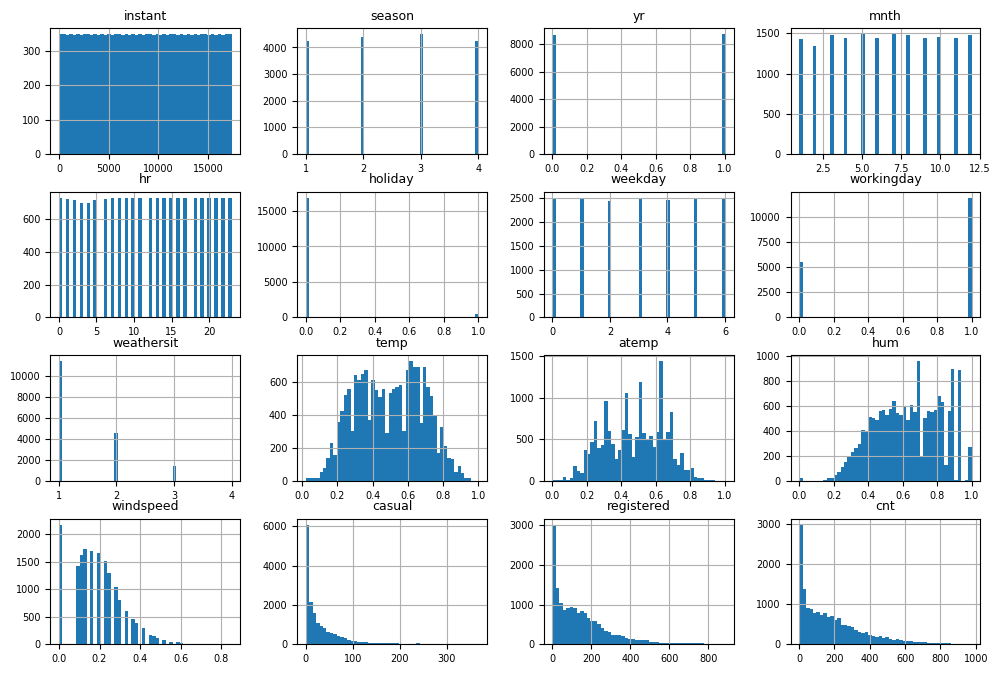
First, we needed to check how the data was distributed across the numeric features. The histogram below showed us that the data included roughly the same amount of instances for each year, season, month, weekday and hour. We also noted that the temperature and the feeling temperature had a reasonable range and shape for year round weather in Washington D.C. The weather situation graph seemed to have none or very few values for the extreme weather situation 4 and we anticipated that we would run into problems when we split the dataset into training and test subsets.
Data Correlation
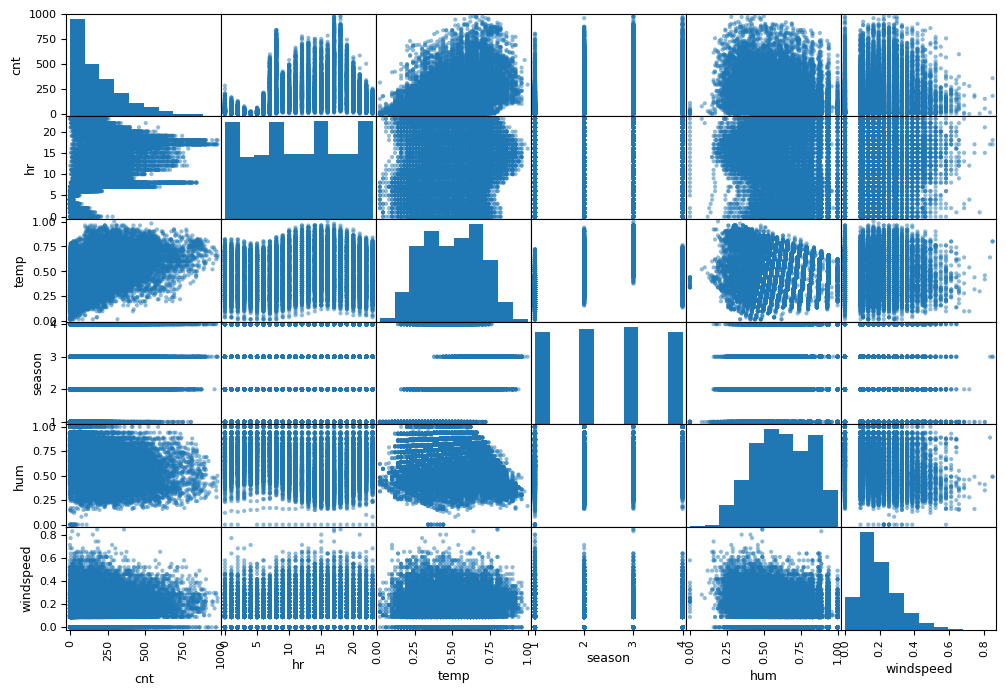
To explore the dataset further, we computed a correlation matrix (shown below) to have an initial understanding about which features may influence the target value, the number of bikes (cnt). The registered and casual columns were highly correlated since the sum of those two columns is the target variable, so we looked at the next highest correlation for more insight. Both temperature columns, the “feels like” and the “actual,” along with the hour and humidity appeared to be promising features.

Next, we created a scatter matrix to visualize some of the larger data correlations. We created the matrix with 6 of the 17 features, which included three features that were correlated to the target variable cnt, one cyclical feature (season) and one with low correlation (windspeed). The temp feature seemed to be the most linearly correlated with the our target variable cnt as depicted in the graph on the first column and the third row.
Methods
Step 1: Split the dataset
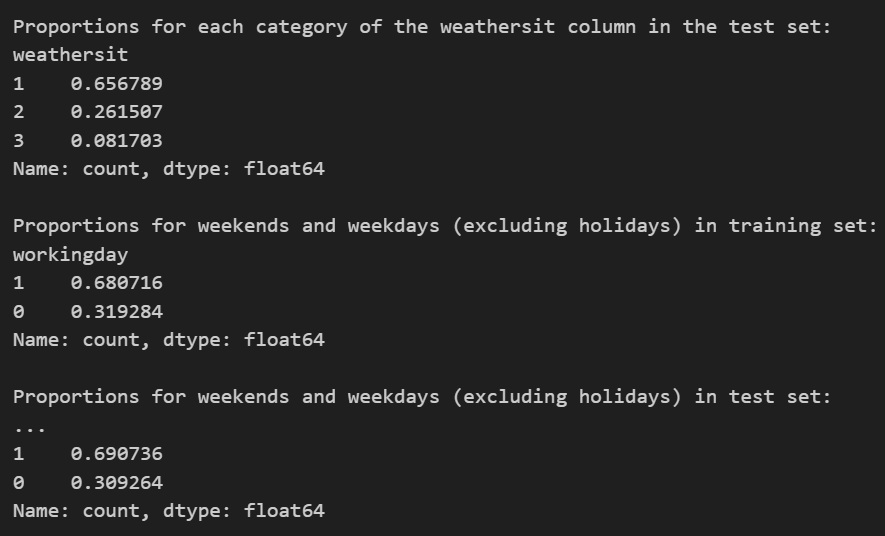
In order to begin training, we needed to split the data into a training set and a test set. To ensure that the training set and the test set had the same proportions for each weather situation, we used stratified split. After the split, eighty percent of the data was assigned to the training set and the other twenty percent to the test set.
We also used several print statements to confirm that the stratified split worked. After running the code, the proportions for the first three weather situations matched well but we noted that no values with the weather situation 4 ended up in the test set since there were so few data points with that particular weather situation. The proportions for the weekdays and weekends were also roughly the same in both the training set and the test set even though we conducted the stratified split on the weather situation feature.
Step 2: Preprocess Training Set
- Remove unnecessary features
First, we removed the unnecessary features including instant, which was only for recording purposes and dteday, which did not provide helpful information to the model since there are many other features that describe the day (season, month, weekday, etc.). Additionally, the casual and registered features were also removed since they were components of our target variable and would interfere with training.
- Scale data
Next, we checked if we needed to scale the data but the data was already normalized.
- Perform One Hot Encoding on categorical columns
We performed One Hot Encoding on the weather situation column since each weather situation could be treated as its own category. Since there were not enough data points with weather situation 4 to split into the test set, we decided to remove the new column weathersit_4 to avoid future issues.
Perform Cyclical Encoding on cyclical features
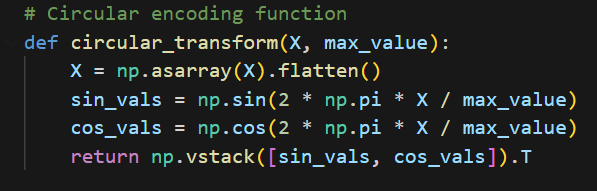
We found a function to encode the cyclical features: season, month, weekday and hour. Cyclical features need to be encoded since, according to Axel Kud, they can “significantly affect the convergence rate of the algorithm and the model’s performance.”
- Drop the encoded columns
Since encoding the features created new columns with the data, we dropped the original columns.
- Recompute the correlation matrix (to see if encoding made a difference)

We recomputed the correlation matrix and the newly encoded features decreased in correlation. The new hr feature, represented as hr_mag, decreased the most. Both temperature values were still correlated and the sin value for the hour feature had a strong negative correlation. We also continued to use the encoded dataset since the new columns reduced the RMSE after we ran the models, as described in the steps below.
Step 3: Run the model on the training set
We ran the LinearRegression, DecisionTreeRegressor, and RandomForestRegressor models on the training set and calculated the RMSE using cross_val_score using the original and encoded data. The encoding decreased the RMSE for the LinearRegression model the most, while the DecisionTree and the RandomForestRegressor remained relatively the same.

*Note: The RMSE values change slightly each time we run the code but the values for the RMSE hovered around the values in the chart above.
Step 4: Run with Grid Search on Training Set
We ran GridSearch to find the best model for Linear, Decision Tree and Random Forest and calculated the feature importance and RMSE for each. We created a bar graph listing the RMSE for all the models that we ran on the training set.
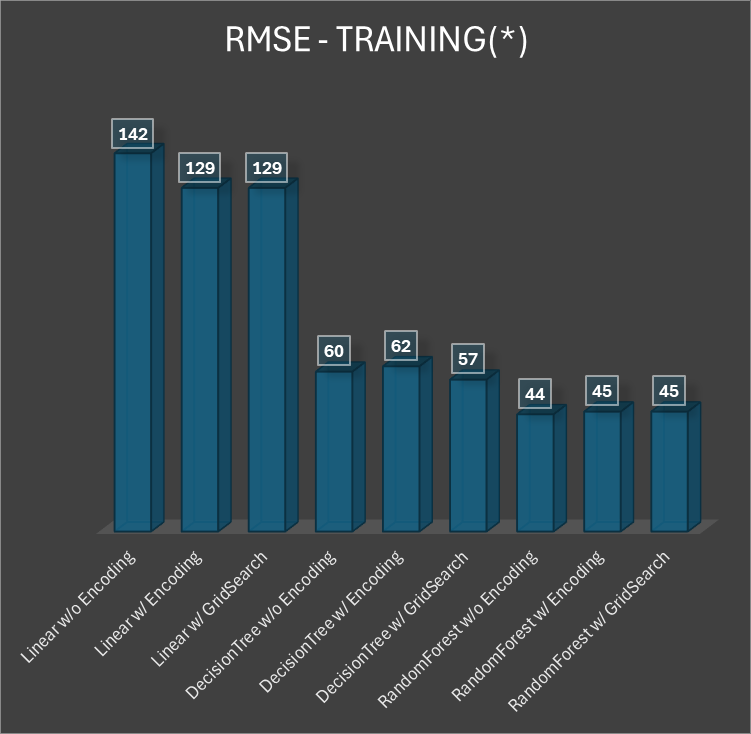
*Note: The RMSE values change slightly each time we run the code but the values for the RMSE hovered around the values in the chart above.
Step 5: Preprocess Test Set
We completed the same preprocessing steps on the test set, and then ran our best model, Random Forest without Grid Search, on the test set. Finally, we computed the root mean squared error (RMSE) of the model’s performance.
Results
We found that the Random Forest model with or without Grid Search performed equally optimally on our training set. After testing multiple models with cross validation, we found that without Grid Search (but with encoding), Random Forest performed the best (RMSE = 45), then Decision Tree (RMSE = 62), and then Linear Regression (RMSE = 129). Recall that the RMSE value of a model’s performance represents the mean number of bikes that the model’s prediction is off by compared to the true number of bikes, so a lower RMSE corresponds to a better model. When we ran the models again, but this time with Grid Search, we found that Random Forest again performed the best (RMSE = 45), then Decision Tree (RMSE = 57), and then Linear Regression (RMSE = 129). Curiously, Grid Search improved the Decision Tree model, but it did not affect the Linear Regression or Random Forest models. Since the Random Forest model without Grid Search was tied with the Random Forest model with Grid Search for the lowest RMSE, we decided to name the Random Forest model without Grid Search our best model in order to minimize computation time and energy. When we ran this best model on our test set, we got an RMSE of 42 and a coefficient of variation of RMSE (CVRMSE) of 22.22%, which means that the model’s typical prediction error is about 22.22% of the average number of bikes. This is a promising indicator of solid model performance.
There are a few reasons why Grid Search didn’t overwhelmingly improve the performance of the models we tested. For algorithms like Random Forest, the model’s default hyperparameters are already well-tuned for general use cases, so using Grid Search to find optimal hyperparameter combinations might not increase the model’s performance substantially. In addition, even though we researched smart values to use in Grid Search’s parameter grid, it’s possible that the values we assigned the parameter grid created a limited search space and were not robust enough to allow Grid Search to improve upon the Random Forest model. We limited the depth and features of the Decision Tree and Random Forest models to ensure a reasonable runtime, but that may have resulted in a shallow grid search unable to increase model performance.
We also looked at some results from someone else on Kaggle who used this dataset for machine learning in the past. They found that almost all of the features in the dataset were significant. We found similar results, as our first correlation matrix shows that the majority of the features are correlated to some degree with the target variable. The other person who worked with this dataset on Kaggle did a time series analysis (predicting future values), though, and we did not, so our models and results are not comparable.
Learnings
This project taught us a lot about the end-to-end machine learning process. Firstly, we learned about cyclical encoding, which we weren’t familiar with. Cyclical encoding is a type of preprocessing that encodes inherently cyclical features (time, season, etc.) in a way that better captures the continuity and closeness of certain feature values to each other. We weren’t aware that this was a necessary preprocessing step before going through this process, but now we know that cyclical encoding can help expose important relationships in our data, like the fact that the weekend is close to Monday and Friday, for example. Upon reflecting on our entire end-to-end process, we realized that preprocessing is the longest and most tedious part of the process! Encoding ordinal features, performing cyclical encoding, and dropping unnecessary columns were all essential steps we had to take before we could apply a machine learning model to our dataset. Consequently, we learned that training and running a machine learning model is surprisingly easy and simple, and it often only involves a few lines of code.
We also discovered that machine learning engineers do not work in a technical vacuum void of critical thinking skills. While machine learning work is undoubtedly very data heavy, machine learning engineers also need to deploy rational thinking skills to make sound, practical decisions about model attributes, applications, and implementations. We engaged in many collaborative discussions throughout the process about high-level execution topics that required thoughtfulness and foresight to make smart business choices beyond our technical work. For example, we decided on our target variable by considering what information would be most helpful for the bike sharing company to have in order to improve their customer experience, and we chose to keep or drop columns in the original dataset based on whether or not they would help us explore relationships in our data in a relevant and productive way.
This connects to the machine learning ethics lecture we had in class, in which we practiced identifying potential types of biases in our data and training processes. Drawing on our critical thinking skills and considering the ethics of our work will help us continue to value the societal impacts of our models as we advance as machine learning engineers. This project has taught us that machine learning is not always a clear-cut process with obvious rules or steps, and each machine learning project is different and has unique goals, needs, and challenges. We also realized that when explaining our decisions and processes to business stakeholders (or teachers!), we need to have robust reasoning to back up our feature engineering and model tuning decisions to explain to audiences that are unfamiliar with our project why the model we have built is optimal, both in terms of logic and fairness.
Finally, we learned that additional model tuning and optimization, specifically in the case of Grid Search, does not always improve the performance of a machine learning model. This is counterintuitive because it seems reasonable to assume that running Grid Search algorithms to optimize model parameter combinations would increase performance, but this is not always the case. This was a surprising and important learning experience. It taught us not to rely too heavily on model tuning methods because they can promote a false sense of confidence and promise. Alternatively, it is more important to examine each step of the machine learning process with a critical eye and test multiple approaches to solving a machine learning problem instead of betting solely on popular optimization techniques.
There were also a couple things that didn’t go as we expected in this project. As we already mentioned, Grid Search did not widely improve model performance. In addition, cyclical encoding did not make a big difference on the correlation matrix once we recomputed it, which was a surprise. We predicted that different features would be more highly correlated with the bike count once we performed cyclical encoding, but cyclical encoding actually decreased the correlation between hour, weekday, and month. This can happen if the features that we cyclically encoded were originally linearly correlated with our target variable, bike count. If these features have a natural linear relationship with our target variable but we use cyclical measures like sin and cosine to recompute the correlation during cyclical encoding, the correlation may be reduced.
Finally, if we were going to do this project again, we would make a few changes to our dataset and process. We would try to find more recent bike sharing data to update our model and make it ready to deploy in the present day because the dataset we used is from 2011 and 2012 and is therefore a bit outdated. We would also test other regression models besides Linear Regression, Decision Tree, and Random Forest to see if we can find a more optimal model.
Conclusion
We found that we can use the Random Forest regression model without Grid Search to best predict the number of bikes that will be rented for a given hour from Capital Bike Share in Washington D.C., U.S.A. Our model yields solid performance metrics and can be used as a reasonable estimator of bike rentals for Capital Bike Share to help the company ensure that they meet their customers’ bike rental needs.
References
We encourage readers to check out the references below to learn more about the dataset and methods we used in this machine learning regression project.
ChatGPT. (2024).
Kud, Axel. “Why We Need Encoding Cyclical Features.” Medium, Medium, 4 Dec. 2023, medium.com/@axelazara6/why-we-need-encoding-cyclical-features-79ecc3531232.
Nemati, Ali. “Linear Regression for Housing Data Using Randomized Search, Cross-Validation, Search Grid, or Combines.” LinkedIn, 1 Apr. 2023, www.linkedin.com/pulse/linear-regression-housing-data-using-randomized-search-ali-nemati/.
Singh, Harbhajan. “Bike Sharing Dataset.” Kaggle, Kaggle, www.kaggle.com/datasets/harbhajansingh21/bike-sharing-dataset/data. Accessed 4 Dec. 2024.
Cover image reference:
Other Kaggle projects that use the same dataset:
https://www.kaggle.com/code/frizmoo/eda-time-series-bike-sharing
https://www.kaggle.com/code/hainescity/bike-dataset-download-and-inspect
Our GitHub repository: